![]()
Codedeploy is one of the deployment service by AWS. The application can
be deployed using either a s3 bucket or a git repository which contains
the deployable content like code, scripts, configurations files,
executables etc.
In this blog post, we are going to deploy a wordpress application in an
elastic, highly available and scalable environment using codedeploy.
Get things ready
Get a copy of the WordPress source code in the local system using git command:
git clone https://github.com/WordPress/WordPress.git /tmp/WordPress
Create Scripts to run your Application. Make a directory .scripts in the WordPress folder:
mkdir -p /tmp/WordPress/.scripts
Create the following shell scripts in the .scripts folder: sudo vim install_dependencies.sh:
#!/bin/bash
yum groupinstall -y "PHP Support"
yum install -y php-mysql
yum install -y nginx
yum install -y php-fpm
Next sudo vim stop_server.sh:
#!/bin/bash
isExistApp=`pgrep nginx`
if [[ -n \$isExistApp ]]; then
service nginx stop
fi
isExistApp=`pgrep php-fpm`
if [[ -n \$isExistApp ]]; then
service php-fpm stop
fi
one more, sudo vim start_server.sh:
#!/bin/bash
service nginx start
service php-fpm start
and finally, sudo vim change_permissions.sh:
#!/bin/bash
chmod -R 755 /var/www/WordPress
Make these scripts executable with this command:
chmod +x /tmp/WordPress/.scripts/*
CodeDeploy uses an AppSpec file which is a unique file that defines the
deployment actions you want CodeDeploy to execute. So along with the
above scripts, create a appspec.yml file
sudo vim appspec.yml
version: 0.0
os: linux
files:
- source: /
destination: /var/www/WordPress
hooks:
BeforeInstall:
- location: .scripts/install_dependencies.sh
timeout: 300
runas: root
AfterInstall:
- location: .scripts/change_permissions.sh
timeout: 300
runas: root
ApplicationStart:
- location: .scripts/start_server.sh
timeout: 300
runas: root
ApplicationStop:
- location: .scripts/stop_server.sh
timeout: 300
runas: root
Now zip the WordPress folder and push it to your git repository.
Creating IAM Roles
Create an iam instance profile and attach AmazonEC2FullAccess policy and also attach the following inline policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:Get*",
"s3:List*"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
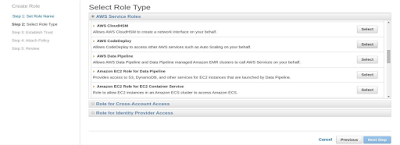
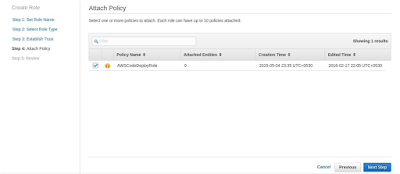
Create a service role CodeDeployServiceRole. Select Role type AWS
CodeDeploy. Attach the Policy AWSCodeDeployRole as shown in the below
screenshots:
How about Scale?
Create an autoscaling group for a scalable environment. Steps below:
Choose an ami and select an instance type for it:
Attach the iam instance profile which we created in the earlier step:
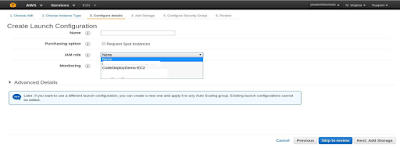
Now go to Advanced Settings and type the following commands in “User
Data” field to install codedeploy agent on your machine (if it’s not
already installed on your ami):
#!/bin/bash
yum -y update
yum install -y ruby
yum install -y aws-cli
sudo su -
aws s3 cp s3://bucket-name/latest/install . --region region-name
chmod +x ./install
./install auto
where, bucket-name represents one of the following based on the instances in the specified region:
- aws-codedeploy-us-east-1
- aws-codedeploy-us-west-2
- aws-codedeploy-us-west-1
- aws-codedeploy-eu-west-1
- aws-codedeploy-eu-central-1
- aws-codedeploy-ap-southeast-1
- aws-codedeploy-ap-southeast-2
- aws-codedeploy-ap-northeast-1
- aws-codedeploy-ap-south-1
- aws-codedeploy-eu-west-2
- aws-codedeploy-ca-central-1
- aws-codedeploy-us-east-2
- aws-codedeploy-ap-northeast-2
- aws-codedeploy-sa-east-1
and region-name will be one of the following:
- us-east-1
- us-west-2
- us-west-1
- eu-west-1
- eu-central-1
- ap-southeast-1
- ap-southeast-2
- ap-northeast-1
- ap-south-1
- eu-west-2
- ca-central-1
- us-east-2
- ap-northeast-2
- sa-east-1
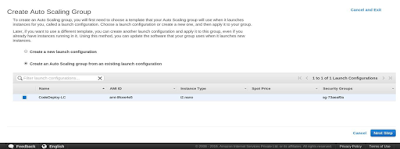
Select Security Group in the next step and create the launch
configuration for the autoscaling group. Now using the launch
configuration created in the above step, create an Autoscaling group.
Select the launch configuration from the given options:
Give the name of the group in the next screen and select a subnet for it.
Keep the remaining settings at its default and create the autoscaling group.
Time to Deploy
Choose Create New Application. Give some name for the application and a name for the deployment group as well.
Select Autoscaling Group in Search By Tags field to deploy the application on the group and select CodeDeployDefault.OneAtATime in the Deployment Config field.
Select ServiceRoleARN for the service role which we created in
the “Creating IAM Roles” section of this post. Go to Deployments and
choose Create New Deployment. Select Application and Deployment Group
and select the revision type for your source code (i.e. an S3 bucket or a
GitHub repository).
On the successful deployment of the application, something like this will appear on the screen:
The WordPress is now deployed on the AutoScaling Group. So when you hit
the public IP of the instance which belongs to the autoscaling group,
nginx test page will load.
Configurring WordPress
Since nginx needs
php-fpm to work with php pages, we need to configure
php-fpm. Also we need to configure WordPress script as well. For this we need to do certain changes in the files as shown below:
sudo vim /etc/php.ini
Uncomment
cgi.fix_pathinfo=0 and change the value from 1 to 0.
sudo vim /etc/php-fpm.d/www.conf
Change
user=nginx and
group=nginx and also make sure the following values are uncommented:
pm.min_spare_servers = 5
pm.max_spare_servers = 35
Add this following script to the configuration file
sudo vim /etc/nginx/conf.d/virtual.conf
server {
listen 80;
server_name example.com;
location / {
root /var/www/WordPress;
index index.php index.html index.htm;
if (-f $request_filename) {
expires 30d;
break;
}
if (!-e $request_filename) {
rewrite ^(.+)$ /index.php?q=$1 last;
}
}
location ~ .php$ {
fastcgi_pass localhost:9000; fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME
/var/www/WordPress$fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_script_name;
include /etc/nginx/fastcgi_params;
}
}
Hit the server name on the browser and It will load the WordPress
Application.To avoid this manual work of configuring the application for
other instances in the AutoScaling Group, you can create an image of
the instance in which you have done these changes and provide the ami of
the created image to the Launch Configuration and update the Launch
Configuration in the AutoScaling Group. Hence, the new instances will be
created with the updated image.
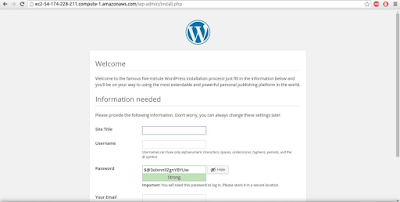
After the successful installation, the wordpress dashboard will appear as shown in the below screenshot:
Make It Stateless
If you would like to scale at will and deploy at will, you need to make
sure that the web/app is stateless. Make sure that you manage plugins in
github repo and static content is stored outside the server, on S3.
To store the static media content of your WordPress Application in an S3 Bucket, we will need a plugin named WP Offload S3.
This plugin automatically copies the media files uploaded by WordPress
into an S3 bucket. But this plugin has a dependency on another plugin,
Amazon Web Services
So, after downloading the both plugins, we got the two zip files of these plugins now. Unzip these files to WordPress/wp-content/plugins
path. If not already done, zip the WordPress folder again, push it to
the git repository and redeploy the application through CodeDeploy using
the CommitID of the latest commit.
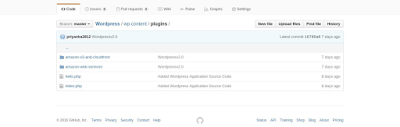
Go to plugins, the two plugins(Amazon Web Services and WP Offload S3)
will be shown. Activate these two plugins. Also, after activating the
Amazon Web Services plugin, AWS console will be added to the left bar.
Go to AWS and define your Access keys and Secret keys in the
wp-config.php.
After activating the WP Offload S3, go to its Settings and enter the
name of the bucket in which you want to store the media contents of your
blog posts. Save the settings.
Now try posting some media content in your blog post.
A folder wp-content will be created in the S3 bucket and the content will get stored in the same folder.
Let there be a loadbalancer
We are now almost done. In order to achieve the 'highly available' part of our initial goal, lets create a loadbalancer :)
Create an Elastic Load Balancer for high availability of your application. Give it a name.
Select a security group for it in the next screen and configure the health checks:
Review and Create.
Now, Attach this ELB with the autoscaling group:
Also, to access the application through the ELB endpoint, add the public DNS of the ELB to the server_name in /etc/nginx/conf.d/virtual.conf.
Happy CodeDeploy-ing! :)

































